
L’ineffectivité du droit d’accès à l’information sur les algorithmes : une étude empirique

Par Philippine Ducros, étudiante-chercheuse (UPEC, Programme de Master-Doctorat Numérique, Politique, Droit), Maxime Zimmer, étudiant-chercheur (UPEC, Programme de Master-Doctorat Numérique, Politique, Droit), Luc Pellissier, maître de conférences en informatique (UPEC, Laboratoire d’algorithmique, complexité et logique) et Noé Wagener, professeur de droit public (UPEC, Laboratoire Marchés, Institutions, Libertés)
Introduction
Alors que de plus en plus de décisions ayant des effets sur les individus sont partiellement ou entièrement automatisées, et que des critiques fortes se déploient à propos de cette automatisation – par exemple à propos du « score de risque » attribué par les caisses d’allocations familiales (CAF) à leurs allocataires, objet d’un exceptionnel contentieux associatif actuellement pendant devant le Conseil d’État[1] –, on entend peu parler, en France, de contestations en justice. Ce silence est d’autant plus surprenant qu’il existe un ensemble assez dense de règles juridiques encadrant l’automatisation et qu’il est de notoriété publique que ces règles sont plutôt mal appliquées.
Afin d’avancer dans la compréhension de cette énigme, et de manière complémentaire à une étude de Nina Lasbleiz[2] publiée au moment même où le présent article est remis à l’éditeur, une analyse empirique systématique de la jurisprudence a été engagée dans le cadre d’activités d’initiation à la recherche du programme de Master-Doctorat Numérique, Politique, Droit de l’université Paris-Est Créteil[3]. Le présent article restitue une partie des résultats de cette recherche en cours, réunissant des étudiants et des enseignants-chercheurs, et se focalise spécifiquement sur le contentieux de l’accès aux informations sur les « algorithmes ». En effet, alors que le droit français encadre aujourd’hui 1° les cas dans lesquels l’automatisation peut se faire, 2° la manière dont cette automatisation se fait et 3° l’information qui est donnée à propos de cette automatisation, il apparaît, d’une part, que c’est le troisième pan de ces règles – celui relatif à ce qu’on appelle couramment un « droit à l’information sur les algorithmes », progressivement doublé d’un droit plus ambitieux « à l’explication »[4] – qui détermine l’effectivité des deux premiers et, d’autre part, que ce troisième pan est mobilisé dans un nombre aujourd’hui substantiel de décisions des juridictions administratives non étudiées de manière systématique à ce stade. Plus précisément, l’étude se concentre sur un corpus de 163 jugements et arrêts rendus entre juin 2022 et août 2024.
La restitution de l’étude de ce corpus s’organise en trois temps. Une première partie présente le cadre juridique applicable et la méthodologie empirique adoptée, permettant de situer le droit d’accès à l’information algorithmique dans l’architecture normative plus large de l’encadrement des décisions automatisées (I). La deuxième partie, qui représente le cœur de l’étude, propose une analyse empirique inédite de la jurisprudence fondée sur l’article L. 311-3-1 du code des relations entre le public et l’administration, en combinant une analyse « externe » et une analyse « interne » (II). Enfin, une troisième partie s’attachera à présenter brièvement quelques conclusions générales – un peu sombres – tirées de l’étude (III).
I. Contexte et méthodologie
A.- Contexte juridique
Rappelons, à titre liminaire, que l’encadrement des traitements algorithmiques dans la prise de décisions repose sur un dispositif juridique à trois niveaux, que nous schématisons en trois axes : « l’autorisation », « le calcul » et « l’accès à l’information ».
Le premier niveau d’encadrement, que nous nommons « autorisation », vise à déterminer les situations dans lesquelles le recours à un traitement algorithmique est soumis à des obligations, interdictions ou permissions. Dans ce cadre, il est bien connu que l’article 22 du RGPD et l’article 47 de la loi Informatique et libertés posent plusieurs principes d’interdiction assortis d’exceptions, notamment lorsque la décision est nécessaire à un contrat, autorisée par le droit ou fondée sur le consentement explicite de la personne concernée. Cette approche permet, en théorie tout du moins, à la CNIL de sanctionner les entités qui auraient recours illégalement à des décisions automatisées, mais elle ouvre aussi la possibilité pour les individus de contester la légalité de telles décisions lorsqu’elles sont rendues en dehors des cas autorisés. Le deuxième axe d’encadrement (le « calcul ») porte, quant à lui, sur le fonctionnement même du traitement algorithmique. Une fois l’usage autorisé, il faut encore que l’algorithme respecte les exigences juridiques substantielles : non-discrimination, pertinence des données traitées, transparence des critères utilisés, etc. Par exemple, en matière de recrutement, une décision fondée sur un critère prohibé tel que l’origine ethnique est illicite, même si l’usage d’un algorithme était autorisé au départ (article L. 1132-1 du code du travail). Ainsi, même lorsque l’autorisation est acquise, la décision peut être annulée si le traitement algorithmique est affecté d’un vice dans son fonctionnement. Bien sûr, ces deux niveaux – autorisation et calcul – ne peuvent produire d’effets concrets que si le destinataire de la décision est informé qu’un algorithme a été utilisé, et comprend comment il a opéré. En l’absence d’information explicite, l’individu est privé de toute possibilité effective de contester la légalité de la décision : il ignore l’existence même du traitement algorithmique, et a fortiori, ne peut en contester ni l’usage ni les modalités. C’est précisément pour remédier à cette asymétrie d’information que le législateur a instauré un droit d’accès à l’information sur les algorithmes, qui se décline sous différentes formes. Il permet, d’une part, d’informer les individus qu’un algorithme a été utilisé pour prendre une décision les concernant et, d’autre part, de leur fournir des explications sur le fonctionnement de l’algorithme ou de leur donner accès à des codes sources.
Au regard de ce qui précède, notre hypothèse de départ est triviale : si le droit d’accès à l’information sur les algorithmes n’est pas effectif, c’est l’ensemble du cadre juridique réglementant les décisions automatisées qui perd de sa substance. C’est pourquoi notre étude se concentre prioritairement sur le troisième axe.
Trois fondements juridiques distincts servent, plus précisément, de support à ce troisième axe : les articles 13 et 14 du RGPD, d’une part – ainsi que, de manière liée, les articles 47 et 119 de la loi Informatique et libertés ; l’article L. 300-2 du code des relations entre le public et l’administration (CRPA), d’autre part ; l’article L. 311-3-1 du même code, enfin. On pourrait y ajouter l’article 86 du règlement sur l’intelligence artificielle, qui ouvre « le droit d’obtenir du déployeur des explications claires et pertinentes sur le rôle du système d’IA dans la procédure décisionnelle et sur les principaux éléments de la décision prise », mais il est très tôt pour l’étudier sérieusement – d’autant qu’il se concentre, rappelons-le, sur les seuls systèmes d’IA dits à « haut risque »[5].
Toutes ces dispositions juridiques sont aujourd’hui bien connues, grâce aux différentes thèses qui y ont été consacrées, notamment celle de Liane Huttner[6] et celle de Sabrina Hammoudi[7]. Si l’on résume les choses brièvement, on dira que les articles 13 et 14 du RGPD prévoient l’obligation de donner, dans l’hypothèse d’une décision ayant pour fondement un traitement algorithmique, « des informations utiles concernant la logique sous-jacente, ainsi que l’importance et les conséquences prévues de ce traitement pour la personne concernée », tandis que l’article 119 de la loi Informatique et libertés évoque, pour les décisions ayant pour fondement un traitement intéressant la sûreté de l’État et la défense, une obligation de donner « les informations permettant de connaître et de contester la logique qui sous-tend le traitement automatisé en cas de décision prise sur le fondement de celui-ci et produisant des effets juridiques à l’égard de l’intéressé ». Quant à l’article 47 de la loi, il prévoit que, pour ce qui concerne spécifiquement les décisions administratives individuelles prises sur le fondement d’un traitement algorithmique, « le responsable de traitement s’assure de la maîtrise du traitement algorithmique et de ses évolutions afin de pouvoir expliquer, en détail et sous une forme intelligible, à la personne concernée la manière dont le traitement a été mis en œuvre à son égard ». L’article L. 300-2 du CRPA opère, lui, sur un tout autre terrain : introduit par la loi pour une République numérique, il confirme que les codes sources utilisés par les administrations peuvent être considérés comme des documents administratifs communicables, et donc accessibles sur demande, sous réserve des exceptions légales (secrets protégés). Reste, enfin, l’article L. 311-3-1 du CRPA qui constitue aujourd’hui le texte de droit administratif le plus explicitement dédié à l’encadrement des décisions prises sur le fondement d’un traitement algorithmique, mais pour ce qui concerne les décisions administratives individuelles seulement. Introduit par la loi du 7 octobre 2016 pour une République numérique, cet article impose deux obligations à l’administration : celle de mentionner explicitement qu’un algorithme a été utilisé pour fonder sa décision, d’une part ; celle de permettre, à la demande de l’administré, la communication des règles qui ont présidé au traitement ainsi que les principales caractéristiques de sa mise en œuvre. Il est à noter que cette mention obligatoire de l’existence d’un traitement algorithmique n’était pas prévue dans le projet de loi initial. Elle a été introduite par amendement au Sénat contre l’avis du gouvernement, précisément pour éviter que le droit d’accès ne demeure un droit « virtuel », c’est-à-dire inopérant faute d’information préalable sur l’existence du traitement.
B.- Méthodologie
Le droit d’accès aux informations sur les traitements algorithmiques est donc pluriforme, et l’objectif de la recherche menée dans le cadre du programme de Master-Doctorat Numérique, Politique, Droit de l’université Paris-Est Créteil consiste à en développer une approche empirique, en vue de comprendre son effectivité réelle en matière de décisions tant administratives que privées. Pour cela, deux campagnes de recherche successives et complémentaires ont été mises en place à l’université Paris-Est Créteil.
La première, menée lors de l’année 2023 et restituée lors d’une journée d’études « Informatique et droit » qui s’est tenue à Créteil le 16 novembre 2023[8], prenait la forme d’une campagne d’exercices de droits en conditions de vie réelle[9]. Quatorze « algorithmes » intervenant dans la prise de décisions d’acteurs publics et privés ont été sélectionnés, avec un souci de variation – certains étaient très simples (comme l’algorithme du tourniquet de métro), d’autres, beaucoup plus complexes (comme l’algorithme d’estimation des risques de fraude fiscale), y compris mobilisant de l’apprentissage-machine. Pour chacun de ces « algorithmes », un, deux ou les trois fondements juridiques[10] servant de support au droit d’accès à l’information, précédemment évoqués, ont été sollicités dans le cadre d’exercices de droit, afin de vérifier, d’une part, s’ils étaient faciles à mobiliser et, d’autre part, s’ils étaient efficaces. Les résultats des tests se sont révélés désastreux : sur quatorze exercices de droits, six réponses seulement ont été obtenues sur le fond ; parmi ces réponses, toutes étaient négatives, à l’exception d’une seule. Pour quatorze exercices de droits mobilisant le droit à la communication d’informations sur la « logique » qui sous-tend l’algorithme (articles 13 et 14 RGPD et 119 de la loi Informatique et libertés), le droit à la communication des « règles » définissant l’algorithme et des « principales caractéristiques » de sa mise en œuvre (article L. 311-3-1 CRPA) et le droit à la communication du « code source » mettant en œuvre l’algorithme (article L. 300-2 CRPA), seul un établissement public, l’établissement public Pôle Emploi, nous aura effectivement communiqué quelque chose, en l’occurrence le code source de son dispositif de priorisation des courriels des demandeurs d’emplois.
La seconde campagne – menée lors de l’année 2024 et dont le présent article restitue une part des résultats – consistait à travailler à partir de bases de données ouvertes (open data) pour comprendre comment les juges, la CNIL et la CADA traitaient effectivement les questions de l’accès aux informations sur les traitements algorithmiques. Ce travail, qui entend développer une approche non pas pointilliste mais systématique des décisions, est encore en cours ; mais le moins qu’on puisse dire est que les premiers résultats produits sont, eux aussi, porteurs de déceptions.
Reprenons les choses dans l’ordre. Pour ce qui concerne l’effectivité du droit d’accès à « la logique sous-jacente » (articles 13 et 14 du RGPD et article 119 de la loi Informatique et libertés), force est de constater qu’à ce stade, la CNIL n’en fait pas grand-chose : elle continue de n’investir qu’avec une très grande prudence ce sujet, après avoir joué un rôle majeur dans le quasi-abandon, au tournant des années quatre-vingt-dix, de l’article 3 initial de la loi Informatique et libertés en vertu duquel « toute personne a le droit de connaître et de contester les informations et les raisonnements utilisés dans les traitements automatisés dont les résultats lui sont opposés »[11]. Pour ce qui concerne l’effectivité du droit d’accès au code source (article L. 300-2 CRPA), le problème est d’un tout autre ordre. L’idée initiale était d’exploiter de manière systématique l’open data des avis de la Commission d’accès aux documents administratifs (CADA) – un poste d’observation central dans la mesure où la saisine de la commission est obligatoire avant tout contentieux sur l’accès aux codes sources entrant dans le champ du CRPA. Or, aussi surprenant que cela puisse paraître, ce travail s’est révélé impossible : la CADA se trouve aujourd’hui dans l’incapacité matérielle de mettre à disposition un jeu complet de ses avis, faute de maîtriser les circuits d’anonymisation. Face à cette situation, l’un des auteurs de l’étude a saisi la CADA pour avoir accès au jeu des avis de la CADA auxquelles la CADA lui refusait l’accès, ce qui, chacun en conviendra, ne manquait pas d’ironie. Dans un avis du 25 janvier 2024[12] en forme de mise en abyme, la CADA constate avec dépit que la CADA ne dispose ni d’un « outil informatique [lui] permettant de procéder de manière automatisée et satisfaisante à l’anonymisation des avis et conseils », ni des forces humaines suffisantes pour le faire « de manière manuelle », et s’accorde généreusement un délai d’un an pour communiquer les avis antérieurs au 1er octobre 2023[13]. Bref, toute étude systématique de la doctrine actuelle de la CADA concernant l’accès aux codes sources est impossible à ce stade, quand bien même la situation s’améliore doucement à mesure que les laborieuses anonymisations manuelles avancent. Le choix a alors été fait de réorienter l’étude systématique du droit d’accès au code source (article L. 300-2 CRPA) vers l’analyse des données ouvertes de la jurisprudence administrative – une open data loin d’être optimale, mais infiniment meilleure que celle de la CADA. Or, il ressort de nos recherches qu’il n’existe presque aucun contentieux devant les tribunaux administratifs à propos de l’accès aux codes sources. Sur la période qui nous intéresse (juin 2022 à août 2024), seuls deux jugements pertinents ont été identifiés, ce qui est une information lourde de sens en soi, mais qui retire largement l’intérêt de constituer un corpus d’étude.
C’est pourquoi notre recherche s’est orientée vers la dernière base légale, l’article L. 311-3-1 du CRPA. L’ouverture des données (open data) de la justice administrative, plus ou moins opérationnelle depuis juin 2022, nous permet, en, effet, de former un corpus réunissant les jugements et arrêts mobilisant l’article L. 311-3-1 du CRPA entre le 23 juin 2022[14] et le 1er septembre 2024. Les données sélectionnées ont alors été référencées dans un tableur organisé en différentes catégories et permettant d’appuyer l’étude empirique[15]. Il importe néanmoins d’émettre certaines réserves quant à la qualité réelle de l’open data de la justice administrative, autrement moins bonne que l’open data de la justice judiciaire : la base de données des décisions de justice administrative est souvent incomplète et jamais documentée ; les métadonnées sont, en outre, parfois de mauvaise qualité (problèmes de codage) ; quant au moteur de recherche proposé depuis février 2024, il n’est pas toujours fiable, car il lui arrive d’omettre certaines décisions rendues ou de présenter plusieurs fois la même décision lorsque plusieurs requêtes ont été jointes.
Sur la période courant de juin 2022 à août 2024, c’est finalement un corpus « nettoyé » de 163 jugements et arrêts des juridictions administratives qui a pu être constitué, sur le critère de la mobilisation de l’article L. 311-3-1 du CRPA aux termes duquel – rappelons-le – « une décision individuelle prise sur le fondement d’un traitement algorithmique comporte une mention explicite en informant l’intéressé » et « les règles définissant ce traitement ainsi que les principales caractéristiques de sa mise en œuvre sont communiquées par l’administration à l’intéressé s’il en fait la demande ».
II.- Analyse empirique des décisions mobilisant l’article L. 311-3-1 du CRPA
L’analyse du corpus jurisprudentiel s’organise en deux temps complémentaires. Une première approche, dite « externe », s’attache à dégager les principales caractéristiques contextuelles des décisions étudiées, afin d’en fournir une vision d’ensemble préalable à l’examen du raisonnement juridictionnel (A). Sur cette base, l’analyse « interne » pourra alors se concentrer sur les considérants des décisions, éclairer les justifications récurrentes données par les juridictions et, en l’occurrence, mettre en évidence les motifs pour lesquels les moyens tirés de l’article L. 311-3-1 du CRPA sont, dans leur écrasante majorité, écartés (B).
A.- Analyse externe : caractéristiques du contentieux
L’utilisation jurisprudentielle de l’article L. 311-3-1 du CRPA apparaît relativement stable dans le temps, avec une moyenne de six décisions de justice rendues chaque mois sur la période étudiée [Figure 1]. On peut donc parler d’un contentieux d’importance marginale, d’une part, et qui évolue peu, d’autre part, ce qui dévoile, c’est le moins qu’on puisse dire, un véritable contraste avec l’ampleur des polémiques suscitées par l’automatisation des décisions dans le secteur public.
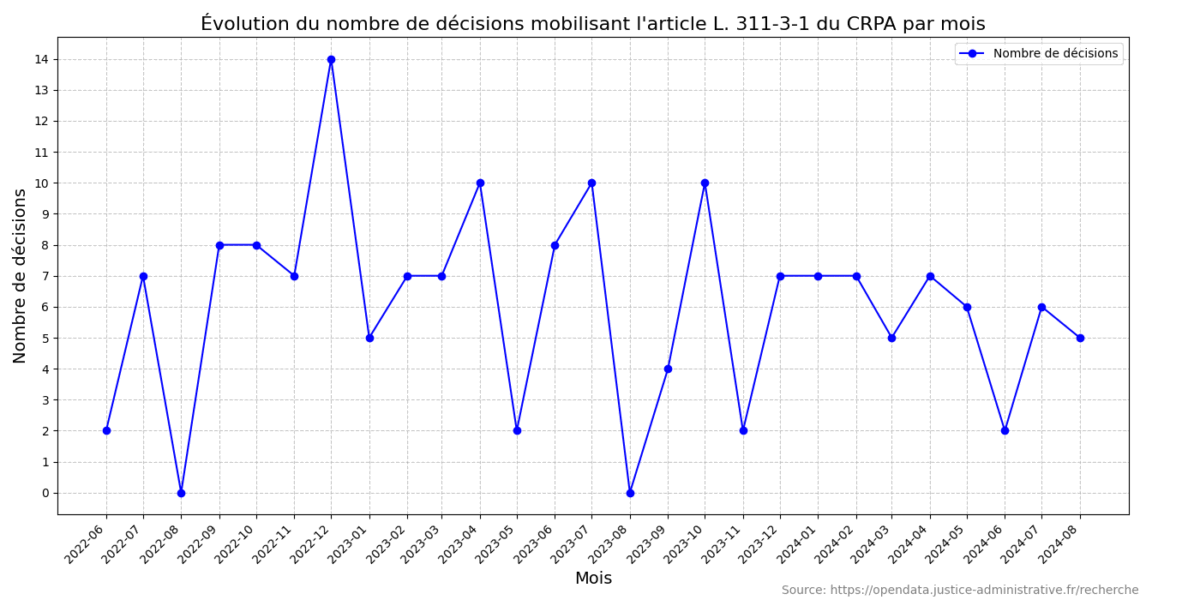
Mais le point essentiel est ailleurs : la nature du contentieux étudié se révèle extrêmement homogène. En effet, 161 des 163 décisions de justice du corpus concernent des litiges relatifs à des versements de prestations sociales. Plus précisément, l’écrasante majorité des jugements et arrêts est rendue à la suite de recours en annulation formés contre des décisions de conseils départementaux et de CAF réclamant des indus de prestations, c’est-à-dire, concrètement, demandant le remboursement d’aides apparemment versées à tort.
Quelques éléments de contexte s’imposent ici. Si l’article L. 311-3-1 est mobilisé dans ces affaires de prestations sociales, c’est parce que les requérants soupçonnent les demandes de remboursement d’indus d’avoir été prises à la suite d’un contrôle humain, certes, mais lui-même décidé consécutivement à un « ciblage algorithmique » en fonction de « scores de risque » automatiquement attribués par les administrations. S’agissant des CAF, en effet, la pratique d’un tel « ciblage » est aujourd’hui bien connue : elle est à l’origine d’une vaste controverse depuis deux ans, après qu’il a été révélé que les caisses « priorisaient » les contrôles par leurs agents en utilisant un algorithme de « scoring » prétendant déterminer quels allocataires sont les plus à risque de fraude. Les critiques de ce « ciblage » sont essentiellement de quatre ordres, que nous résumerons brièvement. D’abord, le système de « scoring » a tendance à reproduire voire à accentuer des biais sociaux. Ensuite, les critères exacts du score ne sont pas publics, si bien que les allocataires ne savent pas pourquoi ils sont contrôlés. Par ailleurs, avec ce ciblage automatisé, la suspicion se trouve placée au cœur du dispositif de contrôle, dans la mesure où des individus se trouvent ciblés sur la base d’une probabilité, et non d’éléments factuels établis qu’il conviendrait de vérifier : le soupçon remplace les indices, en somme. Enfin, il apparaît que beaucoup des « fraudes » détectées sont en réalité des erreurs ou des oublis involontaires, de la part de personnes souvent peu familiarisées avec les démarches administratives, et auxquelles on réclame un remboursement susceptible d’avoir des conséquences dramatiques sur leur vie quotidienne.
Mais ce n’est sans doute pas parce que le « ciblage algorithmique » en matière d’aides sociales est particulièrement polémique que le contentieux se concentre sur ce domaine. Cette concentration doit, en effet, être mise en relation avec un facteur structurel, qui ressort nettement de notre corpus : dans 90 % des affaires, le requérant est représenté par un seul et même avocat, Maître Pierre-Henry Desfarges. Maître Desfarges – avec lequel un entretien a été réalisé dans le cadre de cette étude – est un avocat aujourd’hui spécialisé dans le contentieux des aides sociales, mais qui dispose d’une formation de Master en droit de l’Internet et des systèmes d’information avant d’exercer plusieurs années en tant qu’avocat sur des dossiers liés aux nouvelles technologies. Pour partie au moins, le lien entre l’article L. 311-3-1 et le contentieux des aides sociales est donc contingent : Maître Desfarges le reconnaît volontiers, c’est son intérêt personnel pour le droit du numérique qui a conduit à l’introduction dans le contentieux des aides sociales de cet article créé par la loi pour une République numérique. Dans ces conditions, si l’on ne trouve quasiment que du contentieux des aides sociales dans notre corpus, ce n’est sans doute pas tant parce que ce domaine se prête mieux à l’utilisation de l’article L. 311-3-1, ni même parce qu’il serait davantage exposé aux algorithmes, mais, plus prosaïquement, parce qu’il s’agit du domaine de spécialité du seul avocat qui mobilise régulièrement cet article.
Dans la caractérisation de ce contentieux, trois autres observations importantes peuvent être faites. Premièrement, on remarque que si l’article L. 311-3-1 est effectivement mobilisé dans 163 décisions de justice sur la période étudiée, il l’est au détour, si l’on ose dire, de contentieux en annulation de réclamations d’indus. En effet, l’argument tiré de la méconnaissance de l’article L. 311-3-1 y est conçu comme un moyen parmi d’autres d’obtenir l’annulation de la décision administrative, et non en soi et pour lui-même, et en particulier pas au soutien d’une demande spécifique d’accès aux règles et principales caractéristiques d’un traitement algorithmique. Une seule et unique décision concerne des requérants ayant mobilisé l’article L. 311-3-1 du CRPA pour contester un refus d’accès à des documents administratifs (CE, 24 juillet 2023, n°462778, Association médicale indépendante de formation).
Deuxièmement, il ressort de notre corpus que les juridictions rejettent systématiquement le moyen tiré de l’article L. 311-3-1 – et plus précisément, en fait, le moyen tiré de l’absence de la mention prévue à cet article. Un seul cas fait exception : dans un jugement du 6 décembre 2022 (n° 2009989), sur lequel nous reviendrons, le tribunal administratif de Cergy-Pontoise reconnaît que l’omission de la mention selon laquelle la décision a été prise sur le fondement d’un traitement algorithmique constitue un vice de forme entachant d’illégalité ladite décision (en l’occurrence, une décision de récupération d’indu d’aide au logement). Ce jugement reste toutefois isolé.
Troisièmement, enfin, il est notable que le contentieux mobilisant l’article L. 311-3-1 est cantonné à la première instance, en dépit de son taux d’échec considérable. Alors que les jugements des tribunaux administratifs statuant sur des recours contre une décision de CAF ne sont pas susceptibles d’appel mais encourent directement la cassation devant le Conseil d’État, les requérants ne poursuivent pour ainsi dire jamais leur action après le premier jugement. Deux éléments d’explication peuvent être avancés : le découragement face à une jurisprudence largement défavorable, conjugué à la difficulté, réelle, d’obtenir l’aide juridictionnelle devant le Conseil d’État.
B.- Analyse interne : interprétation des juridictions et portée réelle du droit d’accès aux algorithmes
Une analyse des considérants des décisions (analyse « interne ») permet de mieux comprendre les raisons pour lesquelles les juridictions écartent, dans l’immense majorité des cas, les moyens tirés de l’article L. 311-3-1 du CRPA. Deux lignes d’argument principales structurent cette jurisprudence : une interprétation restrictive de la notion de « fondement » algorithmique, d’une part, et une dévalorisation juridique de l’obligation de mention, d’autre part.
1.- Une interprétation restrictive de la notion de « fondement »
Dans notre corpus, les tribunaux opèrent presque systématiquement une distinction conceptuelle entre le « ciblage algorithmique » (d’un allocataire) et la « décision finale » (de réclamation de l’indu). Le raisonnement suivi est simple : si un traitement algorithmique est souvent utilisé pour identifier des profils à risque de fraude, la décision de récupération de l’indu reste formellement prise par un agent assermenté, après contrôle sur pièce ou enquête. Les juges en déduisent que la décision finale repose sur une appréciation humaine. Dans la mesure où l’article L. 311-3-1 ne concerne que les décisions administratives individuelles prises « sur le fondement d’un traitement algorithmique », ils écartent alors le moyen tiré de la violation de cet article et, dans bien des cas, le qualifient d’inopérant. Pour les juges, donc, il ne fait pas de doute que si le ciblage algorithmique permet de déclencher un contrôle, il ne sert en rien de fondement aux conclusions qui sont tirées par l’administration au terme du contrôle déclenché. Chacun conviendra que cela revient, de la part des juges, à découper un seul et même « process » administratif, celui de la lutte contre l’erreur et la fraude. Certes, il n’y aurait pas eu de réclamation de l’indu s’il n’y avait pas eu de contrôle, et il n’y aurait pas eu de contrôle s’il n’y avait pas eu de ciblage algorithmique ; mais qu’importe : aux yeux des juges presque unanimes, la chaîne est peut-être la même, mais elle se sépare en deux maillons bien distincts, le début de la chaîne et sa fin.
À ce stade, il est difficile de dire si une telle séparation est susceptible d’être remise en question par la désormais célèbre jurisprudence SCHUFA Holding de la Cour de justice de l’Union européenne (CJUE, 7 décembre 2023, SCHUFA Holding, C-634/21)[16]. Dans cette affaire, en effet, la CJUE a jugé que le « scoring » de solvabilité effectué par la société SCHUFA, bien qu’étant une étape préalable à la décision finale d’octroi ou de refus de crédit par une banque, constitue en lui-même une décision individuelle automatisée au sens de l’article 22 du RGPD. Le juge européen s’appuie, pour cela, sur le constat selon lequel ledit « scoring » affecte « de manière significative » des personnes « de façon similaire » aux actes qui produisent des effets juridiques concernant ces personnes. La question est inévitable : un tel raisonnement ne se transposerait-il pas à la situation française, pour remettre en cause le découpage strict entre « ciblage algorithmique » et « décision finale » ? Il est tentant de faire cette transposition, et d’ailleurs, dans un récent rapport, la Défenseure des droits la tente[17]. Mais la comparaison atteint vite ses limites, car dans la décision de la CJUE, il s’agit de reconnaître au « scoring » sa qualité de « décision », et non de fusionner « scoring » et refus de crédit. Il est un peu vain, ceci dit, de spéculer sur le sujet tant qu’un juge français ne s’est pas expressément prononcé. À tout le moins peut-on se demander si les requérants n’auraient pas plutôt intérêt à attaquer la décision de ciblage en elle-même, et non la seule décision de récupération de l’indu – quitte, d’ailleurs, à forcer un peu la main du juge français quant aux contours, de toutes façons mal définis, de la « décision administrative individuelle ».
Indépendamment de ce point, il n’est pas inintéressant de remarquer que la jurisprudence administrative française n’est pas parfaitement au clair quant au sens et à la portée de l’article L. 311-3-1 du CRPA. Deux formulations distinctes, qui pourraient s’interpréter comme deux prises de positions différentes sur l’article L. 311-3-1, apparaissent en effet dans notre corpus. Alors que l’article L. 311-3-1 dispose qu’il s’applique aux décisions administratives individuelles prises « sur le fondement d’un traitement algorithmique », certains jugements – huit, pour être précis – mentionnent, pour rejeter l’application de cette disposition, que « la décision n’a pas été prise sur le seul fondement d’un traitement algorithmique ». Cette formulation suggère que l’article ne s’appliquerait que dans les cas de décisions intégralement automatisées, ce qui serait une interprétation réductrice du texte. D’autres décisions – au nombre de cinq – affirment, au contraire, que le texte s’applique « lorsqu’un traitement algorithmique a fondé, en tout ou partie, une décision individuelle », étant précisé qu’une de ces décisions est rendue par le Conseil d’État. Dans cette seconde configuration, le juge ne requiert plus de traitement automatisé complet de la décision (c’est-à-dire sans intervention humaine) pour mobiliser l’article L. 311-3-1, et le champ d’application du texte s’élargit en conséquence. La première lecture ne convainc pas beaucoup, en réalité : exiger que le traitement algorithmique ait servi de « seul fondement » à la décision prise témoigne d’une confusion entre le CRPA et la loi Informatique et libertés. Certes, l’article 47 de la loi Informatique et libertés mentionne en son second alinéa que les décisions administratives individuelles ayant pour seul fondement un traitement automatisé de données personnelles doivent respecter les dispositions de l’article L. 311-3-1 du CRPA, mais, pour autant, ces deux dispositions sont distinctes : l’article L. 311-3-1 n’a pas vocation à être rétracté sur les seules décisions entièrement automatisées auxquelles s’applique l’article 47.
Quoi qu’il en soit, dans un cas comme dans l’autre, les moyens sont presque toujours écartés au nom de la distinction, apparemment cardinale, entre le ciblage algorithmique et la décision finale. Il est à noter que ce raisonnement est renforcé par une exigence un peu inattendue au point de vue de la preuve : plusieurs décisions, cinq précisément, reprochent au requérant de ne pas démontrer l’intervention d’un traitement algorithmique dans la décision attaquée, alors même que ce traitement n’a par définition pas été mentionné – ce qui rend logiquement cette preuve inaccessible. C’est faire peser la charge de la preuve sur un requérant qui ne la détient pas et n’a pas la possibilité de la détenir puisque cette information lui a été masquée, à rebours des règles gouvernant l’attribution de la charge de la preuve devant le juge administratif, en vertu desquelles, s’il incombe, en principe, à chaque partie d’établir les faits nécessaires au succès de sa prétention, les éléments de preuve qu’une partie est seule en mesure de détenir ne sauraient être réclamés qu’à celle-ci (CE Section, 20 juin 2003, n° 232832, Société Etablissements Lebreton ; CE, 26 novembre 2012, n° 354108, Mme Cordière).
2.- Une réduction de la portée juridique de la mention obligatoire
Une dernière observation importante peut être tirée de notre corpus. Un grand nombre de jugements (37 jugements) précisent, dans leurs motifs de rejet, que la mention imposée par l’article L. 311-3-1 du CRPA – celle selon laquelle la décision administrative individuelle a été prise sur le fondement d’un traitement algorithmique – n’est pas une condition de légalité de la décision, mais une simple formalité destinée à permettre à l’administré d’exercer son droit d’accès aux règles et principales caractéristiques du traitement algorithmique. La formule couramment retenue, à la manière d’un obiter dictum, est quelque peu étrange : « le moyen tiré de ce que les décisions ne comporteraient aucune des mentions exigées par les articles L. 311-3-1 et R. 311-3-1-2 du code des relations entre le public et l’administration, qui prévoient seulement, au demeurant, leur communication à tout intéressé qui en ferait la demande, ne peut qu’être écarté comme inopérant ». Elle est non seulement étrange sur le plan syntaxique (ce qui doit être communiqué, à en croire la formule, ce sont… les mentions !), mais elle l’est aussi sur le fond : avec l’usage de la locution adverbiale « au demeurant », la mention obligatoire semble être ramenée à une simple question de droit à communication, insusceptible d’entacher la décision d’illégalité si elle venait à être absente.
Or, il faut rappeler qu’à l’origine, l’amendement qui introduit la mention obligatoire de l’article L. 311-3-1 vise à donner de l’effectivité au reste de l’article, considérant que le droit d’obtenir les règles et principales caractéristiques de l’algorithme qui aurait fondé une décision individuelle resterait virtuel si le destinataire n’obtenait pas l’information selon laquelle un tel traitement avait été effectué. On se souvient que lors de la préparation de la loi pour une République numérique, le gouvernement s’oppose à l’idée d’une telle mention obligatoire, considérant qu’il faut faire confiance aux administrations pour juger de l’opportunité d’informer les administrés de l’existence d’un traitement algorithmique[18]. Le Sénat n’est pas convaincu et obtient finalement l’inscription dans la loi de l’obligation, pour les administrations, de mentionner expressément l’usage de traitements algorithmiques[19]. La question revient cependant dans les débats deux ans plus tard, au cours des discussions sur la future loi du 20 juin 2018 relative à la protection des données personnelles. Constatant la réticence des administrations à se conformer à l’article L. 311-3-1, et pour lever tout doute quant à l’interprétation qu’en ferait le juge, la commission des lois du Sénat propose de mentionner expressément la sanction de « nullité » pour un acte administratif pris sur le fondement d’un traitement algorithmique qui ne comporterait pas la mention obligatoire de l’article L. 311-3-1[20]. Le gouvernement accepte finalement de se saisir de cette proposition, mais instaure – délibérément ou non – une confusion en déplaçant la sanction explicite de nullité dans l’article 47 de la loi Informatique et libertés (autrefois article 10), alors que cet article est applicable uniquement aux décisions entièrement automatisées[21]. C’est doublement désastreux : d’une part, le gouvernement laisse à croire que la mention ne devient obligatoire qu’après 2018, lorsque la sanction apparaît explicitement dans la loi Informatique et libertés, alors que le Sénat entendait seulement rendre non ambigu le fait que le non-respect de l’obligation de 2016 entraîne l’annulation de l’acte concerné ; d’autre part, et surtout, il rétracte la conséquence de « nullité » sur les seules décisions fondées exclusivement sur un algorithme, alors que la rédaction de l’article L. 311-3-1 de 2016 permettait vraisemblablement déjà l’annulation des décisions fondées en tout ou partie sur un traitement algorithmique qui ne le mentionnaient pas expressément.
Bref, la confusion introduite par la modification de 2018 pourrait laisser penser que l’article L. 311-3-1 ne dispose d’aucune effectivité, sauf dans le cas des décisions entièrement automatisées entrant dans le champ de l’article 47 de la loi Informatique et libertés. Rien n’interdit de penser, néanmoins, que l’article L. 311-3-1 conserve une portée autonome : théoriquement, il devrait permettre d’annuler une décision fondée partiellement sur un traitement algorithmique si la mention obligatoire est absente, et ce, quand bien même la loi ne prévoit pas expressément que cette absence est « à peine de nullité ».
Ce dernier point soulève un débat intéressant, et de première importance. Il faut rappeler que le juge administratif sanctionne la violation des règles de forme obligatoires uniquement lorsqu’elles sont substantielles, comme un défaut de signature de l’acte ou une motivation insuffisante. Or, dans le cas de l’article L. 311-3-1, il est possible de défendre l’idée que l’absence des mentions relatives au traitement algorithmique empêche l’accès aux règles et principales caractéristiques du traitement, et donc entrave l’accès à la motivation, ce qui pourrait ouvrir la voie à une annulation pour défaut de motivation[22] – un vice insusceptible d’être « danthonysé »[23]. Bien sûr, cela suppose de considérer que le droit d’accès aux règles et principales caractéristiques est l’adaptation, pour les décisions prises sur le fondement d’un traitement algorithmique, du droit à la motivation tel qu’il est prévu au livre II du CRPA, alors même que des différences existent – au premier rang desquelles le fait que les informations prévues à l’article L. 311-3-1 ne peuvent être obtenues que si l’intéressé en fait la demande, alors que la motivation ne nécessite, elle, aucune démarche particulière[24]. Notre corpus de jurisprudence montre qu’on est loin de ce genre de débat, cependant : les juges semblent convaincus que l’article L. 311-3-1 est une formalité spécifique du droit d’accès aux documents administratifs, et se trouvent confortés dans ce sens par le positionnement de la disposition dans le livre III du CRPA. C’est le cœur du problème, en fait : l’information sur l’automatisation n’est pas vue par le juge comme un élément relevant de la substance même de la décision finalement prise au terme du calcul, mais simplement comme une formalité de transparence administrative, dont le non-respect est extérieur à la décision elle-même. Ce faisant, néanmoins, les juges vident largement de sa substance d’origine l’article L. 311-3-1 du CRPA et entravent une voie d’annulation qui semblait pourtant légitime pour contraindre les administrations à se conformer à la loi, à l’ère où les décisions tendent à être rendues de manière toujours plus automatisée et comportent des motivations constituées par la machine.
III. Conclusions
L’analyse empirique du droit d’accès à l’information sur les traitements algorithmiques, tel qu’il est encadré principalement par l’article L. 311-3-1 du CRPA, révèle donc une ineffectivité systémique, tant dans la pratique administrative que dans la réponse juridictionnelle.
D’un point de vue théorique, il est certain que le droit d’être informé de l’usage d’un algorithme dans une décision individuelle, et de pouvoir accéder aux règles qui gouvernent ce traitement, est essentiel à l’exercice effectif des droits des administrés, au sens où, si le droit à l’information est en deçà d’un droit à l’explication – sur lequel se focalise aujourd’hui la discussion –, il n’en constitue pas moins une garantie première pour les individus. Pourtant, en pratique, ce droit est vidé de sa substance par plusieurs mécanismes convergents. D’un côté, les administrations, dans leur grande majorité, n’intègrent pas les mentions requises, et ne donnent que très rarement suite aux demandes d’explication ou de communication de code source. De l’autre, les juridictions administratives adoptent une lecture sévère du champ d’application de l’article, en distinguant strictement les phases de ciblage et de contrôle ou encore en considérant que l’absence de mention s’apparente à une simple irrégularité formelle sans effet sur la légalité de la décision, vidant ainsi l’obligation de toute portée contentieuse. Cette triple défaillance aboutit à une forme d’opacité juridique sur l’usage des algorithmes dans la sphère publique. Elle traduit une résistance implicite à l’exigence de transparence numérique, dans un contexte où les administrations semblent peu enclines, en réalité, à documenter ou à justifier la part de l’automatisation dans leurs décisions.
Il apparaît également que l’architecture actuelle du droit est elle-même en cause. La coexistence de plusieurs textes issus du RGPD, de la loi Informatique et libertés et du CRPA, combinée à une sanction explicite de « nullité » réservée aux seules décisions entièrement automatisées (article 47 de la loi de 1978), engendre un flou juridique sur le régime applicable aux décisions partiellement fondées sur un algorithme. Ce flou est exploité par les administrations pour minimiser leurs obligations, et entériné par les juridictions qui s’évertuent à réduire les conséquences de l’absence de mention des traitements algorithmiques.
Bref, à travers cette étude empirique dont cet article n’est qu’un premier pan, il ressort que le droit d’accès à l’information algorithmique est, dans son état actuel, largement inopérant. Or, nous l’avons dit, cette inopérance entraîne par ricochet une défaillance du dispositif juridique global d’encadrement des décisions algorithmiques, car en l’absence de signalement de leur usage, ni l’autorisation ni le calcul algorithmique lui-même ne peuvent être sérieusement contestés. Consolons-nous, alors, en nous disant que du côté des algorithmes du secteur privé, c’est sans doute bien pire encore.
[1]Communiqué de presse de La Quadrature du net et de 14 autres organisations, « L’algorithme de notation de la CNAF attaqué devant le Conseil d’État par 15 organisations », 16 octobre 2024 [en ligne : https://www.laquadrature.net/2024/10/16/lalgorithme-de-notation-de-la-cnaf-attaque-devant-le-conseil-detat-par-15-organisations/ (consulté le 30 avril 2025)].
[2]Nina Lasbleiz, « Le contentieux des décisions administratives automatisées », RFDA, 2025, p. 211. On citera également l’étude précurseure de droit comparé (Pays-Bas, États-Unis, France) de Lucie Cluzel-Métayer, « Le contrôle juridictionnel embryonnaire des processus décisionnels algorithmiques », in Coll., L’action publique et le numérique, coll. Colloques, n° 47, Société de législation comparée, 2021, p. 63.
[3]Le programme de Master-Doctorat Numérique, Politique, Droit de l’UPEC (Graduate Program Numérique, Politique, Droit) est un parcours du Master de droit du numérique de cette université. Il se veut une formation de Master d’un type nouveau, dans laquelle les étudiant·es ne suivent pas seulement des enseignements en informatique (50 % des enseignements) et en droit (50%), mais s’immergent durant deux années à l’intérieur des laboratoires de l’université, pour se former à la recherche par la recherche. L’objectif est d’emmener tout ou partie de ces étudiant·es vers des projets de thèse.
[4]Liane Huttner, La décision de l’algorithme. Étude de droit privé sur les relations entre l’humain et la machine, préf. Judith Rochfeld, Lefebvre Dalloz, coll. Nouvelles Bibliothèque des thèses, 2024, p. 470 et s. (d’une façon générale, si nous ne renvoyons pas systématiquement à la thèse de Liane Huttner dans l’article, il va sans dire que nos recherches sont largement redevables de cette gigantesque étude). Sur la question spécifique de l’explicabilité, v. également Denis Merigoux, Marie Alauzen, Justine Banuls, Louis Gesbert et Émile Rolley, De la transparence à l’explicabilité automatisée des algorithmes : comprendre les obstacles informatiques, juridiques et organisationnels, INRIA, Rapport de recherche n° 9535, 2024 [en ligne : https://inria.hal.science/hal-04391612 (consulté le 30 avril 2025)].
[5]Pour une présentation des enjeux de l’explicabilité dans le règlement sur l’IA et son articulation avec les règles existantes, v. Liane Huttner, « Intervention humaine, contrôle humain et explicabilité : propos sur l’articulation entre le règlement sur l’intelligence artificielle et le RGPD », RDSS, 2024, p. 757.
[6]Liane Huttner, La décision de l’algorithme…, préc.
[7]Sabrina Hammoudi, Algorithmes et droit administratif [thèse], Université de Montpellier, 2024.
[8]https://univ-droit.fr/recherche/actualites-de-la-recherche/manifestations/50693-informatique-et-droit
[9]Cette campagne a été menée en lien avec Éloi Barbier, doctorant en droit public à l’UPEC (sujet de thèse : Le raisonnement juridique au prisme des algorithmes).
[10]Tous les fondements juridiques ne peuvent pas toujours être utilisés, en effet : par exemple, le premier fondement juridique – celui tiré des articles 13 et 14 du RGPD – ne peut pas être mobilisé s’il n’y a pas de « traitement de données à caractère personnel » ; ou le troisième fondement juridique – celui tiré de l’article L. 311-3-1 du CRPA – ne peut pas être mobilisé s’il n’y a pas de « décision administrative individuelle ».
[11]Sur ce quasi-abandon, v. Noé Wagener, « L’ambition déçue de la loi Informatique & Libertés de réglementer les traitements algorithmiques », 1024. Bulletin de la société informatique de France, 2023, n° 22, p. 21-31
[12]CADA, 25 janvier 2024, avis n° 20237734, Noé Wagener c. Commission d’accès aux documents administratifs.
[13]Délai que l’autorité gardienne de l’ouverture des informations publiques n’a finalement pas respecté, précisons-le au passage.
[14] Date de la première décision du corpus, mentionnant l’article L.311-3-1. L’open data a été alimentée de décisions en trois périodes distinctes : d’abord celles du Conseil d’Etat (30 septembre 2021), puis les cours administratives d’appel (31 mars 2022) et enfin les tribunaux administratifs (30 juin 2022).
[15]Cette base de données sera prochainement mise en ligne, en même temps que le présent article sera versé sur la plateforme HAL.
[16] Sur cette décision, v. la contribution de Mathilde Unger dans ce dossier.
[17]Défenseur des droits, Algorithmes, systèmes d’IA et services publics : quels droits pour les usagers ? [rapport], 2024, p. 13.
[18]Assemblée nationale, Projet de loi pour une république numérique (1ère lecture), 2e séance du mardi 19 janvier 2016.
[19]Sénat, Projet de loi pour une république numérique (1ère lecture), Séance du mardi 26 avril 2016.
[20]Rapport n°350 de Sophie Joissains, sénatrice, fait au nom de la commission des lois du Sénat sur le projet de loi, adopté par l’Assemblée nationale relatif à la protection des données personnelles, p. 120 (14 mars 2018).
[21]Assemblée nationale, Projet de loi, modifié par le Sénat, relatif à la protection des données personnelles, 2ème lecture, 1ère séance du jeudi 12 avril 2018.
[22]Pour une position différente, v. Nina Lasbleiz, « Le contentieux des décisions administratives automatisées », RFDA, 2025, p. 211.
[23]À noter que ce n’est pas exactement la voie retenue par le Tribunal administratif de Cergy-Pontoise, dans son jugement du 6 décembre 2022 (n° 2009989) précédemment évoqué. Si le tribunal administratif de Cergy-Pontoise reconnaît que l’omission de la mention selon laquelle la décision a été prise sur le fondement d’un traitement algorithmique entache d’illégalité ladite décision, il se contente de l’expression générique de « vice de forme » (« […] la décision attaquée qui ne comporte pas la mention visée à l’article L. 313-3-1 précité est entachée d’un vice forme »).
[24]Sur cette différence avec le « principe même de motivation des actes administratifs qui est […] de rendre les motifs de la décision directement visibles pour l’administré, sans nécessiter de démarche de sa part […] », v. Sabrina Hammoudi, Algorithmes et droit administratif [thèse], Université de Montpellier, 2024, p. 211-213.
